Research: Computer Vision
Spatial-Temporal Visual Inspections with Novel View Synthesis (JCCE 2026)
On February, 2026
Researcher: Max Midwinter, Kay Han
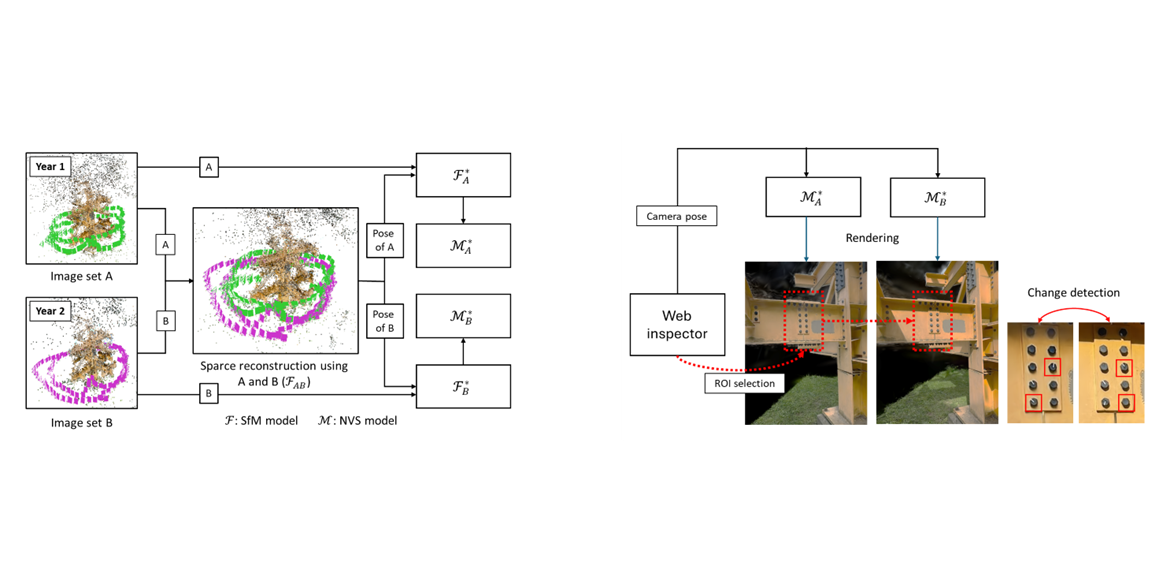
Description: Visual inspections are key to structural health monitoring (SHM). Deep computer vision can automate these inspections but ignores temporal context—how a structure has changed between inspections. We propose a method using novel view synthesis to spatially synchronize temporally separate inspection images, producing pixel-aligned image pairs of a region of interest. We validated the approach by detecting simulated bolt loosening on the Steel Tree sculpture and applied it to cellular tower asset management. An open-source web viewer is also provided to visualize changes.
Citation: Max Midwinter*, Kay Han*, and Chul Min Yeum, “Spatial-Temporal Visual Inspections with Novel View Synthesis,” accepted at Journal of Computing in Civil Engineering (2025).
Graph-Attention Network for Building Damage Assessment (ISPRS Congress 2026)
On January, 2026
Researcher: Fuad Hasan, Ali Lesani
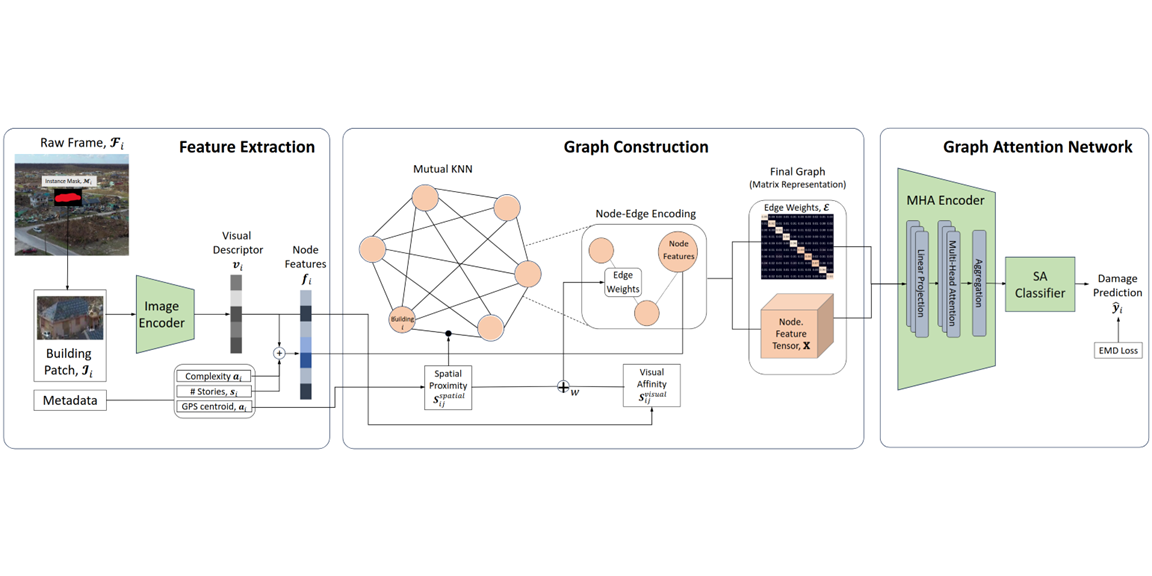
Description: Rapid building damage assessment after hurricanes is critical for emergency response and resource allocation. Traditional ground surveys are slow, hazardous, and subjective. While UAV remote sensing with CNNs has advanced automation, these models operate at pixel or object level, missing spatial relationships within disaster zones. Damage patterns exhibit strong spatial autocorrelation. This paper leverages Graph Attention Networks (GATs) to model spatial dependencies by representing buildings as graph nodes and their relationships as edges, enabling the model to weigh neighboring structures’ influence on damage assessment. Using the DoriaNET dataset from Hurricane Dorian (2019), our GAT model outperforms CNN-based approaches, producing more coherent damage maps suited to real-world disaster management.
Citation: Fuad Hasan*, Ali Lesani*, Chul Min Yeum, and Rodrigo Costa, “Graph-Attention Network for Spatially-Aware Post-Hurricane Building Damage Assessment from UAV Imagery,” accepted at ISPRS Congress 2026.
Structured 3D Gaussian Splatting with LiDAR (ISPRS Congress 2026)
On January, 2026
Researcher: Huaiyuan Weng, Huibin Li
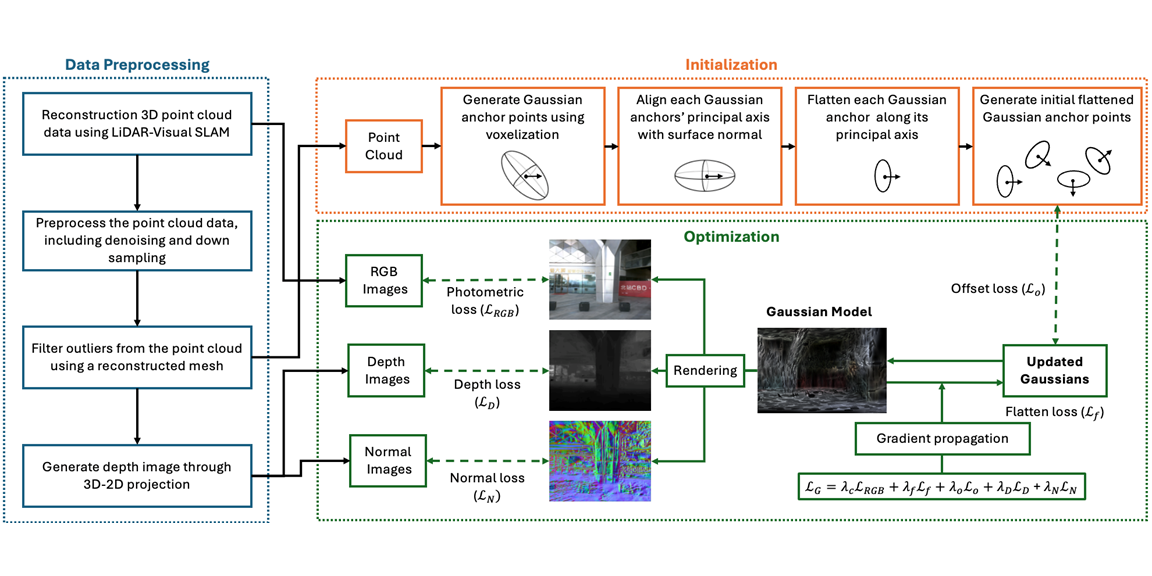
Description: We present Structured-Li-GS, a lightweight Gaussian Splatting pipeline leveraging LiDAR–inertial–visual SLAM. It achieves high-quality 3D reconstructions with fewer Gaussians by training on accurate, dense, colorized point clouds. Primitives are anchored using sub-sampled points with ellipsoidal parameters initialized from local surface geometry. Training integrates photometric, flattening, offset, depth, and normal losses guided by the dense point cloud, eliminating Gaussian densification. We validate using a custom hardware-synchronized LiDAR–camera handheld scanner. Experiments on benchmark and real-world datasets show Structured-Li-GS surpasses state-of-the-art methods with fewer Gaussians.
Citation: Huaiyuan Weng*, Huibin Li*, and Chul Min Yeum, “Structured-Li-GS: Structured 3D Gaussian Splatting with LiDAR Incorporation and Spatial Constraints,” accepted at ISPRS Congress 2026.
Learning monocular depth estimation for defect measurement (SHM 2025)
On February, 2025
Researcher: Max Midwinter, Zaid Abbas Al-Sabbag
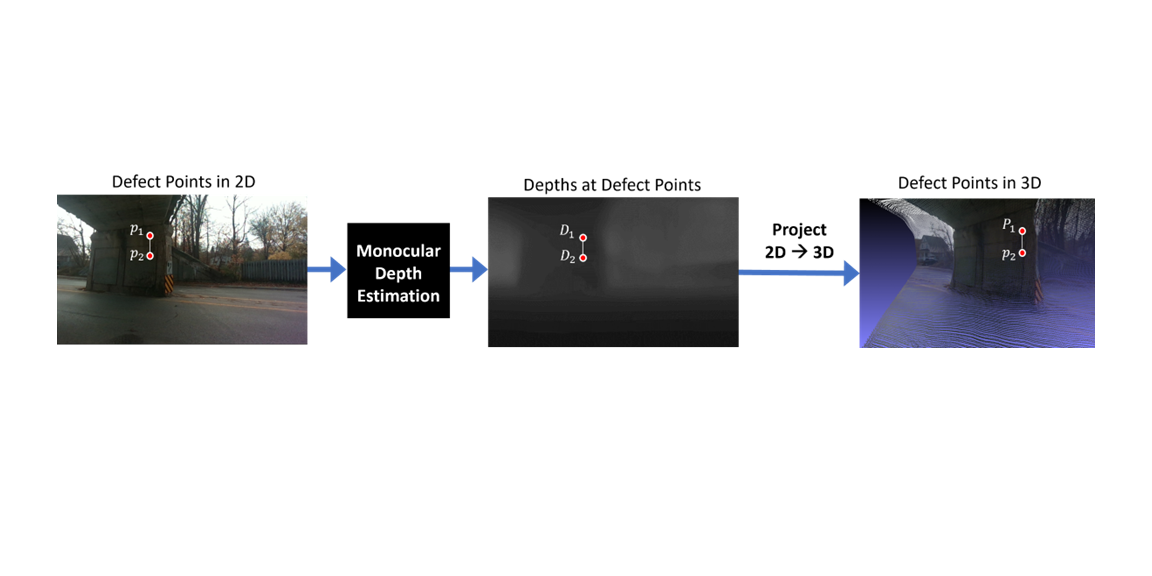
Description: Deep learning methods can automatically detect and segment structural defects from images, but quantifying defect size from a single image remains challenging without supplementary sensors. We propose using monocular depth estimation to recover 3D geometry from a single image for defect quantification. While this field has advanced with open RGB-D datasets, none exist for civil engineering. We address this by building a LiDAR-based RGB-D dataset and testing monocular depth estimation for quantifying defects in civil
Citation: Max Midwinter*, Zaid Abbas Al-Sabbag*, Rishabh Bajaj*, and Chul Min Yeum, “Learning monocular depth estimation for defect measurement from civil RGB-D dataset,” Structural Health Monitoring (2025): 14759217251316532.
Project page: Github
Distributed collaborative inspections through smart infrastructure metaverse (AutoCon 2024)
On Setptember 2024
Researcher: Zaid Abbas Al-Sabbag
Description: We propose Smart Infrastructure Metaverse (SIM), a real-time distributed system enabling synchronous structural inspections by on- and off-site inspectors. On-site inspectors use Mixed Reality (MR) headsets to overlay digital information on structures, while remote inspectors use Virtual Reality (VR) headsets to interact with a pre-built 3D point cloud and aligned 360° imagery. Both can annotate, measure, and assess defects collaboratively. A multi-shot localization algorithm ensures spatial alignment, and field experiments on a railroad bridge demonstrate system feasibility with two MR and one VR inspector.
Citation: Zaid Abbas Al-Sabbag*, Chul Min Yeum, and Sriram Narasimhan, “Distributed Collaborative Inspections through Smart Infrastructure Metaverse,“ Automation in Construction, 165, 105503, (2024).
Defect Detection and Quantification for Visual Inspection (AOMJAH 2024)
On February, 2024
Researcher: Rishab Bajaj, Max Midwinter, Zaid Abbas Al-Sabbag
Description: We propose an unsupervised semantic segmentation method (USP), based on unsupervised learning of image segmentation inspired by differentiable feature clustering coupled with a novel outlier rejection and stochastic consensus mechanism for mask refinement. Also, based on the segmentation region, damage regions are reconstructed in 3D for quantitative evaluation.
Citation: Rishabh Bajaj*, Zaid Abbas Al-Sabbag*, Chul Min Yeum, and Sriram Narasimhan, “3D Dense Reconstruction for Structural Defect Quantification,“ ASCE Open: Multidisciplinary Journal of Civil Enginering, 04024001 (2024).
Unsupervised Semantic Segmentation with Pose Prior (CACAIE 2023)
On April 2023

Researcher: Max Midwinter, Zaid Abbas Al-Sabbag
Description: Supervised single-shot semantic bounding box detectors are widely used for vision-based inspections but face several limitations, including excessive background capture under perspective changes, costly domain-specific labeling, and redundant or inconsistent detections across video frames. Modern augmented reality and robotic systems provide image sequences with camera pose information that can help overcome these challenges. Leveraging pose as prior knowledge, we propose an unsupervised semantic segmentation method (USP) based on differentiable feature clustering with outlier rejection and stochastic consensus mask refinement. USP is validated for spalling quantification using a Microsoft HoloLens 2, with additional sensitivity analysis under varying environmental and operational conditions.
Citation: Max Midwinter*, Zaid Abbas Al-Sabbag*, Chul Min Yeum, “Unsupervised Semantic Segmentation with Pose Prior”, Computer-Aided Civil and Infrastructure Engineering, 38(17), 2455-2471, (2023).
Multi-output Image Classification to Support Post-Earthquake Reconnaissance (JPCF 2022)
On October, 2022

Researcher: Ju An Park, Max Midwinter
Description: After hazard events, reconnaissance teams collect large volumes of images to assess structural performance and improve design codes. Manually labeling these images is time-consuming and requires domain expertise. Deep learning has enabled rapid classification, but existing methods are limited to simple schemas with mutually exclusive or independent classes. This paper introduces a comprehensive multi-level hierarchical classification schema and a multi-output deep convolutional neural network (DCNN) with hierarchy-aware prediction for rapid post-earthquake image classification. The model outperformed multi-label and multi-class alternatives by F1-score and was deployed to a web platform, the Automated Reconnaissance Image Organizer, for easy image organization.
Citation: Ju An Park*, Xiaoyu Liu, Chul Min Yeum, Shirley J. Dyke, Max Midwinter*, Jongseong Choi, Zhiwei Chu, Thomas Hacker, Bedrich Benes, “Multi-output Image Classification to Support Post-Earthquake Reconnaissance,” Journal of Performance of Constructed Facilities, 36(6), 04022063, (2022).
Project page: Github
Enabling Human-Machine Collaboration through Mixed Reality (ADEI 2022)
On August 2022
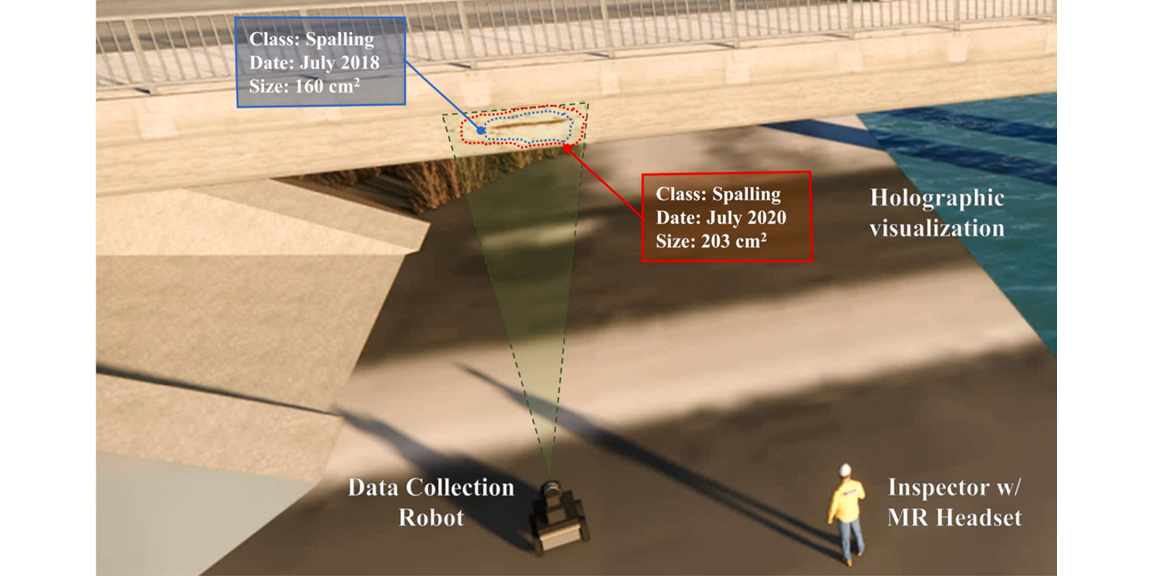
Researcher: Zaid Abbas Al-Sabbag
Description: We propose Human–Machine Collaborative Inspection (HMCI), an end-to-end system that enables collaboration between inspectors using Mixed Reality (MR) headsets and a robotic platform for structural inspections. The robot collects images and depth data to generate 3D maps, which are processed offsite to detect and localize defects. Using holographic visualization and precise head tracking, the MR headset overlays detected defects onto the real scene, allowing inspectors to supervise and refine automated results in near real time. A single-shot localization method provides spatial alignment between the robot and headset. We validate HMCI in a lab setting using a Microsoft HoloLens 2 and Turtlebot2 equipped with an Azure Kinect, demonstrating successful 3D reconstruction, defect (ROI) detection, and anchored MR visualization. To our knowledge, HMCI is among the first systems integrating robots and MR headsets for collaborative structural inspection.
Citation: Zaid Abbas Al-Sabbag*, Chul Min Yeum, Sriram Narasimhan, “Enabling Human-Machine Collaboration in Infrastructure Inspections through Mixed Reality,” Advanced Engineering Informatics, 53, 101709, (2022).
Interactive Defect Quantification through Extended Reality (ADEI 2022)
On January 2022
Researcher: Zaid Abbas Al-Sabbag
Description: A new visual inspection method that can interactively detect and quantify structural defects using an Extended Reality (XR) device (headset) is proposed. The XR device, which is at the core of this method, supports an interactive environment using a holographic overlay of graphical information on the spatial environment and physical objects being inspected. By leveraging this capability, a novel XR-supported inspection pipeline, called eXtended Reality-based Inspection and Visualization (XRIV), is developed. Key tasks supported by this method include detecting visual damage from sensory data acquired by the XR device, estimating its size, and visualizing (overlaying) information on the spatial environment.
Citation: Zaid Abbas Al-Sabbag*, Chul Min Yeum, Sriram Narasimhan, “Interactive Defect Quantification Through Extended Reality”, Advanced Engineering Informatics, 51, 101473, (2022)
Project page: Github
Learning-based Image Scale Estimation Using Surface Textures (CACAIE 2021)
On August 2020
Researcher: Ju An Park
Description: Computer vision-based inspection solutions used for detection of features, such as structure components and defects often lack methods to determine scale information. Knowing image scale allows the user to quantitatively evaluate regions-of-interest to a physical scale (e.g. length/area estimations of features). To address this challenge, a learning-based scale estimation technique is proposed. The underlying assumption is that the surface texture of structures, captured in images, contains enough information to estimate scale for each corresponding image (e.g., pixel/mm). In this work, a regression model is trained to establish the relationship between surface textures, captured in images, and scales. A convolutional neural network is trained to extract scale-related features from textures captured in images. Then, the trained model can be exploited to estimate scales for all images that are captured from a structure’s surfaces with similar textures.
Citation: Ju An Park*, Chul Min Yeum, Trevor D. Hrynyk, “Learning-based Image Scale Estimation using Surface Textures for Quantitative Visual Inspection,” Computer-Aided Civil and Infrastructure Engineering, 36(2), 227-241, (2021).
Project page: Github
Post-Event Reconnaissance Image Documentation using Automated Classification (JPCF 2018)
On December, 2018
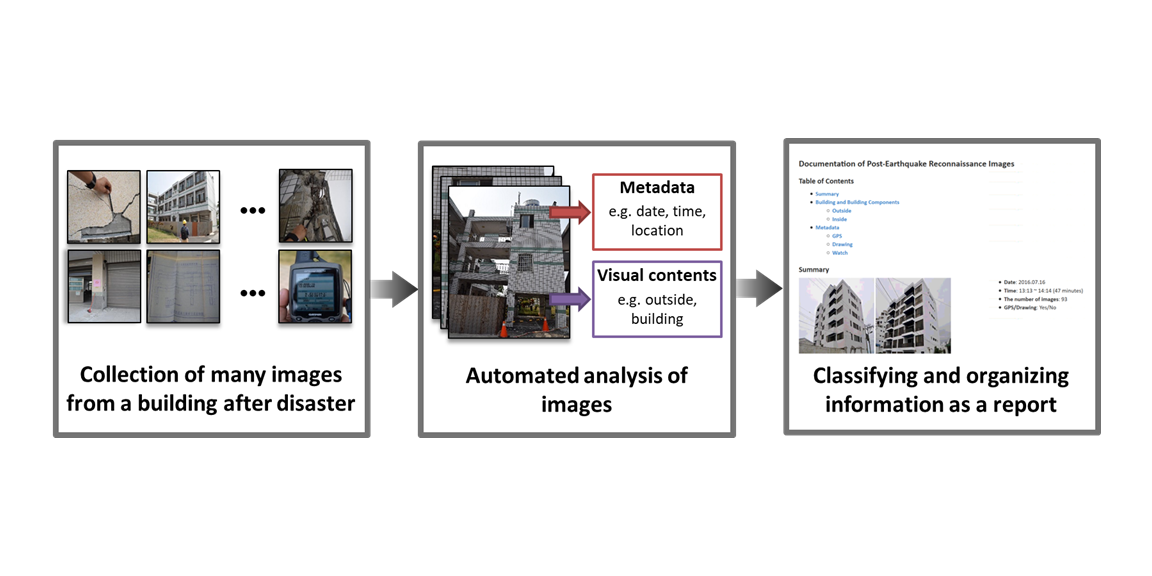
Researcher: Chul Min Yeum
Description: Reconnaissance teams collect perishable post-disaster data, primarily through images of building exteriors and interiors, along with metadata such as GPS, timestamps, drawings, and measurements. Because large volumes of diverse images must be documented quickly and accurately, this paper presents an automated approach for efficient organization and reporting. Deep convolutional neural networks extract key visual features, and a field-informed schema structures the data. Classifiers trained on past earthquake datasets automatically categorize images and generate building-level reports.
Citation: Chul Min Yeum, Shirley J. Dyke, Bedrich Benes, Thomas Hacker, Julio A. Ramirez, Alana Lund, and Santiago Pujol, “Post-Event Reconnaissance Image Documentation using Automated Classification,” Journal of Performance of Constructed Facilities, 33(1), (2018). Editor’s Choice Selection (2019).
Autonomous Image Localization (SHM 2019)
On March, 2018
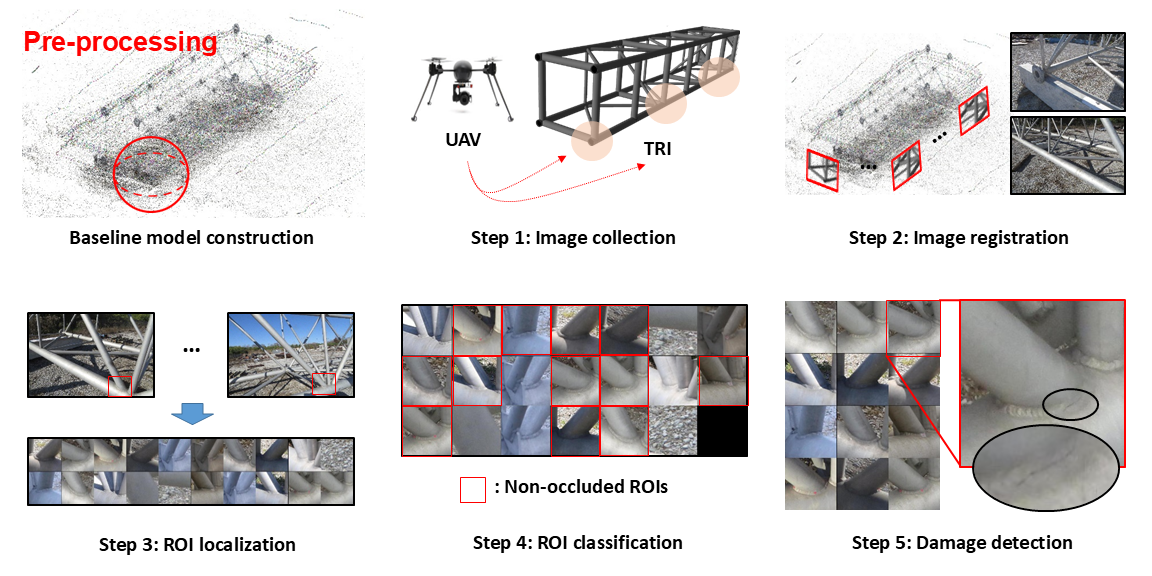
Researcher: Chul Min Yeum
Description: A novel automated image localization and classification technique is developed to extract the regions-of-interest (ROIs) on each of the images, which contain the targeted region for inspection (TRI). ROIs are extracted here using structure-from-motion. Less useful ROIs, such as those corrupted by occlusions, are then filtered effectively using a robust image classification technique, based on convolutional neural networks. Then, such highly relevant ROIs are available for visual assessment. The capability of the technique is successfully demonstrated using a full-scale highway sign truss with welded connections.
Citation: Chul Min Yeum, Jongseong Choi, and Shirley J. Dyke, “Automated Region-of-interest Localization and Classification for Vision-based Visual Assessment of Civil Infrastructure,” Structural Health Monitoring 15, no. 3 (2019).
Project page: Github
Visual Data Classification in Post-Event Building Reconnaissance (Eng. Struct 2018)
On January 2018,
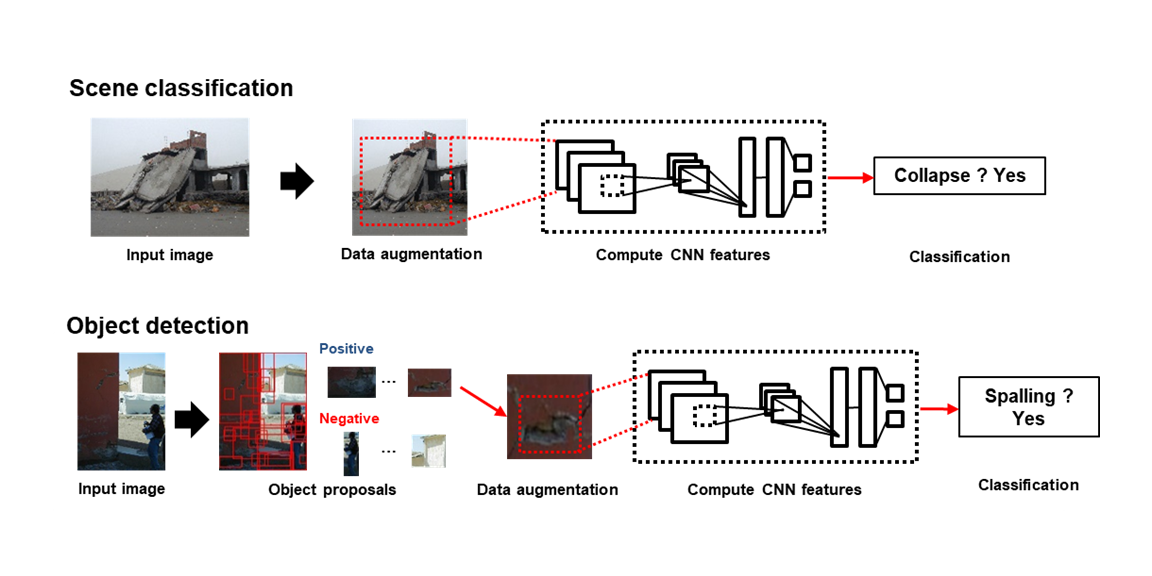
Researcher: Chul Min Yeum
Description: Post-event reconnaissance teams collect perishable visual data to learn from disasters, generating vast amounts in just days. However, only a small portion is annotated for scientific use due to tedious manual analysis. We introduce a method for autonomous post-disaster evaluation by processing large visual datasets using convolutional neural networks (CNNs). Image classification and object detection extract target content automatically from collected images. The technique is demonstrated through collapse classification and spalling detection in concrete structures using images from past earthquakes.
Citation: Chul Min Yeum, Shirley J. Dyke, and Julio A. Ramirez, “Visual Data Classification in Post-Event Building Reconnaissance,” Engineering Structures 155 (2018): 16-24.
Vision-Based Automated Crack Detection (CACAIE 2015)
On May, 2015
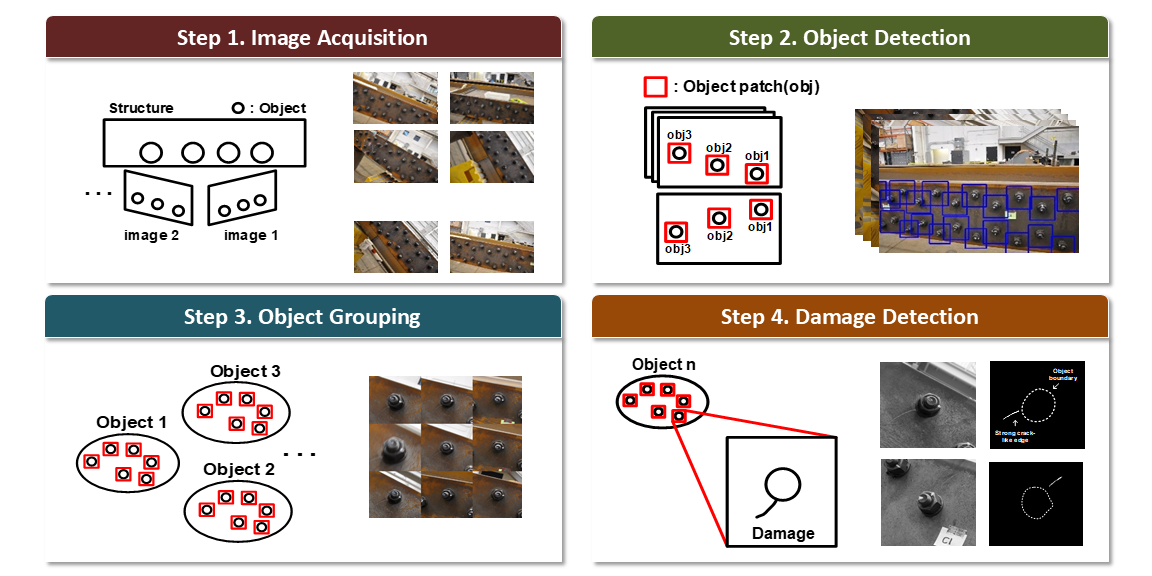
Researcher: Chul Min Yeum
Description: A new vision-based visual inspection technique is proposed by automatically processing and analyzing a large volume of collected images from unspecified locations using computer vision algorithm. By evaluating images from many different angles and utilizing knowledge of a fault’s typical appearance and characteristics, the proposed technique can successfully detect faults on a structure.
Citation: Chul Min Yeum and Shirley J Dyke, “Vision-Based Automated Crack Detection for Bridge Inspection,” Computer-Aided Civil and Infrastructure Engineering 30, no. 10 (2015): 759-770. Recipient of 2015 Innovation Award for this journal
Project page: Github